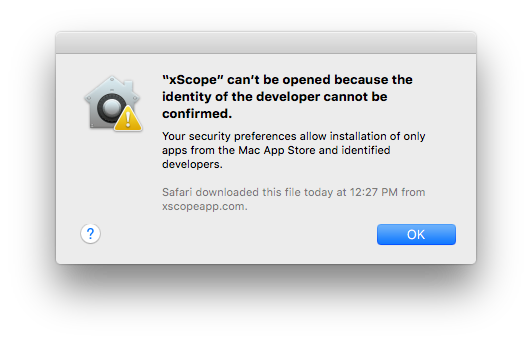
After releasing a update for xScope with fixes for El Capitan, I launched the app on a fresh install of the OS and was greeted by this dialog:
I had tested the build on Yosemite, and it passed without any problems:
$ spctl -a -v ~/Downloads/xScope.app
/Users/craig/Downloads/xScope.app: accepted
source=Developer ID
Clearly there is something new with Gatekeeper in El Capitan. As the author of a tool used by so many early adopters, I often get the job of figuring out what’s new with code signing. Lucky me :-)
I quickly filed a Radar about the problem. This led to feedback from Apple that helped me understand why Gatekeeper rejected my app. The change in El Capitan has the potential to affect a lot of developers (including the big guys), so it’s time to share what I learned.
(If you’re one of those people that claims that “Radar never works”, then that last paragraph just proved you wrong.)
When I ran the spctl tool on El Capitan, I saw an “obsolete resource envelope” error:
$ spctl -a -v --raw xScope.app
xScope.app: rejected
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>assessment:authority</key>
<dict>
<key>assessment:authority:source</key>
<string>obsolete resource envelope</string>
<key>assessment:authority:weak</key>
<true/>
</dict>
<key>assessment:cserror</key>
<integer>-67003</integer>
<key>assessment:remote</key>
<true/>
<key>assessment:verdict</key>
<false/>
</dict>
</plist>
This is a sign that there’s a problem with the code signature. In the past, this has been caused by a change to the signature version number (from 1 to 2). In El Capitan, the cause is more stringent code signature checks.
(Note that I also used the --raw option. According to the man page, “This is useful … to access newly invented assessment aspects that spctl does not yet know about.”)
The functional equivalent to spctl -a is the following codesign command. The --deep option checks any embedded code (such as the Sparkle framework.) Note that --strict is a new option in El Capitan (so new, that it’s not documented yet):
$ codesign --verbose=4 --deep --strict xScope.app
--prepared:/Users/craig/Downloads/xScope.app/Contents/Frameworks/Sparkle.framework/Versions/Current/.
xScope.app: unknown error -67003=fffffffffffefa45
In subcomponent: /Users/craig/Downloads/xScope.app/Contents/Frameworks/Sparkle.framework
file modified: …/Sparkle.framework/Versions/Current/Resources/fr.lproj/fr.lproj
file modified: …/Sparkle.framework/Versions/Current/Resources/fr_CA.lproj
Gatekeeper is rejecting xScope because it thinks some files in Sparkle have been modified after the code signature was generated. This seemed unlikely since the frameworks are code signed during the copy build phase and our automated build process creates a ZIP archive just after the app bundle is created.
I dug around in the application package contents and saw the following:
$ ls -ls Sparkle.framework/Versions/Current/Resources/fr_CA.lproj
8 lrwxr-xr-x@ 1 craig staff 84 Jul 22 12:31 Sparkle.framework/Versions/Current/Resources/fr_CA.lproj
-> /Users/andym/Development/Build Products/Release/Sparkle.framework/Resources/fr.lproj
$ ls -ls Sparkle.framework/Versions/Current/Resources/fr.lproj/fr.lproj
8 lrwxr-xr-x@ 1 craig staff 84 Jul 22 12:31 Sparkle.framework/Versions/Current/Resources/fr.lproj/fr.lproj
-> /Users/andym/Development/Build Products/Release/Sparkle.framework/Resources/fr.lproj
Well, well, well.
Gatekeeper rejected the app because I’m using Sparkle 1.5b6. The framework has symlinks to paths on a Mac that I doubt Andy Matuschak uses anymore. That’s completely reasonable: those symlinks could just as easily point to something a lot more damaging than a non-existent directory.
The --strict option currently checks the validity of symlinks. You can point a symlink at a path in your own application package, /System or /Library, but nowhere else. The code signing rules also allow language translations to be removed, but if they are present they must be unmodified.
The quick fix for this problem was to remove the invalid symlinks; a new build passes the same check without any problems:
$ codesign --verbose=4 --deep --strict xScope.app
--prepared:/Users/craig/Downloads/xScope.app/Contents/Frameworks/Sparkle.framework/Versions/Current/.
--validated:/Users/craig/Downloads/xScope.app/Contents/Frameworks/Sparkle.framework/Versions/Current/.
--prepared:/Users/craig/Downloads/xScope.app/Contents/Frameworks/YAML.framework/Versions/Current/.
--validated:/Users/craig/Downloads/xScope.app/Contents/Frameworks/YAML.framework/Versions/Current/.
xScope.app: valid on disk
xScope.app: satisfies its Designated Requirement
A better solution is to update to a newer version of Sparkle. The project was dormant from 2008 to 2014, so many of us didn’t realize that the team behind the project is doing regular updates again.
Many of your customers will be downloading and running your app on the El Capitan public beta: you should do the codesign --deep --strict check on any new releases to avoid customer support issues. It’s also likely that a similar check will be performed for you when the Mac App Store eventually allows submissions for 10.11.
And let’s get together again when 10.12 is released! In the meantime, enjoy this new release of xScope on Apple’s new release of OS X.